
 Автор:
Автор: Цель алгоритма k-средних – разбить наш набор данных на k похожих пакетов.
В результате группировки можно будет определить метку, связанную с каждым элементом набора.
Именно поэтому данный метод классифицируется как обучение без использования наблюдения, в отличие от методов, в которых метка предоставляется модели вместе с данными.
Содержание
Схема алгоритма
Рассмотрим такой набор данных:
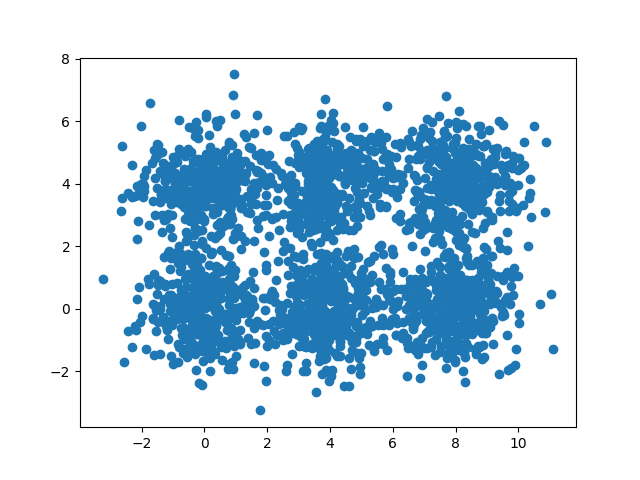
Визуально можно заметить, что существует шесть множеств точек. Сходимость алгоритма будет заключаться в их разделении на эти шесть групп.
Данный алгоритм является итерационным и на каждом шаге уточняет свое решение. Алгоритм будет итеративно перемещать k центров наборов (называемых центроидами) к точкам, к которым они ближе всего.
Шаги алгоритма :
- позиционирование k центроидов;
- для каждой итерации
- связываем каждую точку набора данных с ближайшим центроидом,
- переместим k центроидов в центры ближайших к ним точек.
Алгоритм останавливается при достижении максимального числа итераций или когда центроиды больше не перемещаются.
Инициализация центроидов
Существует несколько стратегий размещения центроидов на старте работы алгоритма:
- разместить их произвольно;
- посчитать равномерно распределенные элементы;
- любым образом разместить их за пределами набора данных.
Однако следует помнить, что на результат работы алгоритма влияют начальные позиции центроидов. Это будет видно на иллюстрациях далее в этой статье.
Итерации в алгоритме
Понятие близости между точкой и центроидом остается на ваше усмотрение.
В случае геометрического набора данных на плоскости, понятие близости может быть реализовано евклидовым расстоянием.
В более общем случае расстояние между двумя точками a и b может быть выражено в n измерениях суммой квадратов расстояний по каждому измерению.
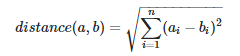
Каждая точка будет связана с центроидом, к которому она ближе всего, затем центроид переместится в сторону центра этих точек.
for p in range(nb_points):
# рассчитывается расстояние от точки p до каждого центроида
distances = [ distance( dataset[p] , c) for c in centroids]
# какой центроид ближайший?
idCentroideNear = np.argmin(distances)
# помещаем точку p в список точек, связанных с каждым центроидом
centroidsNearest[idCentroideNear].append(dataset[p])Code language: PHP (php)Перемещение центроида осуществляется путем вычисления среднего значения точек по каждому параметру (здесь x и y)
for c in range(nb_centroids):
meanx = np.mean([centroidsNearest[c][p][0] for p in range(len(centroidsNearest[c])-1)])
meany = np.mean([centroidsNearest[c][p][1] for p in range(len(centroidsNearest[c])-1)])
# если средние x и meany не меняются, алгоритм сработал, и мы можем остановить итерацию
centroids[c][0] = meanx
centroids[c][1] = meanyCode language: PHP (php)Сближение
В зависимости от начальных положений наших центроидов мы можем получить несколько различных сближений:
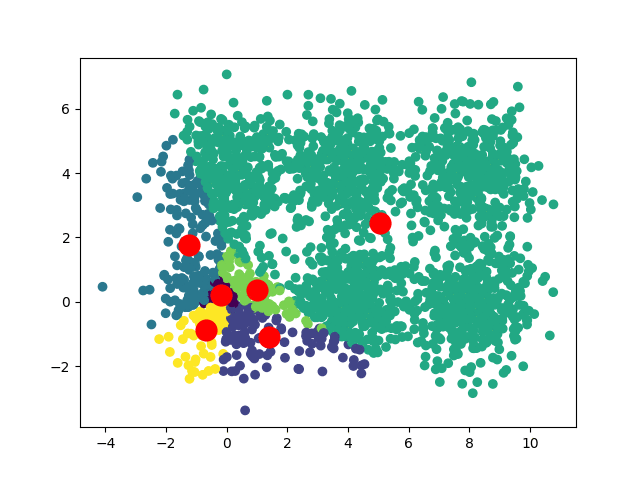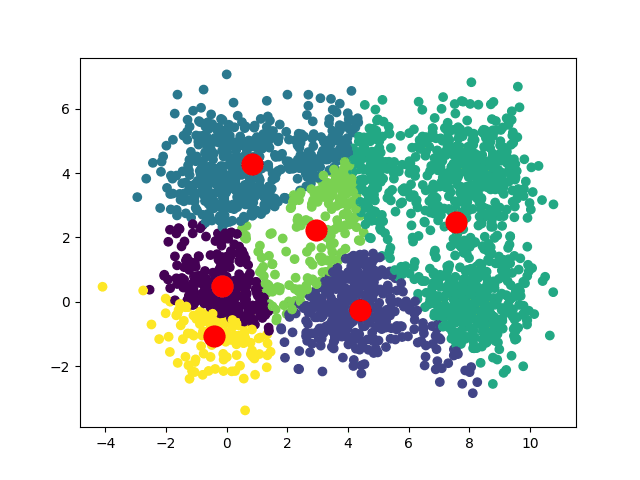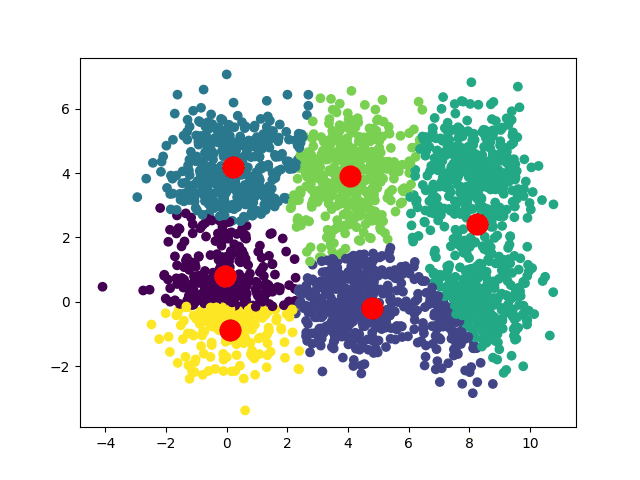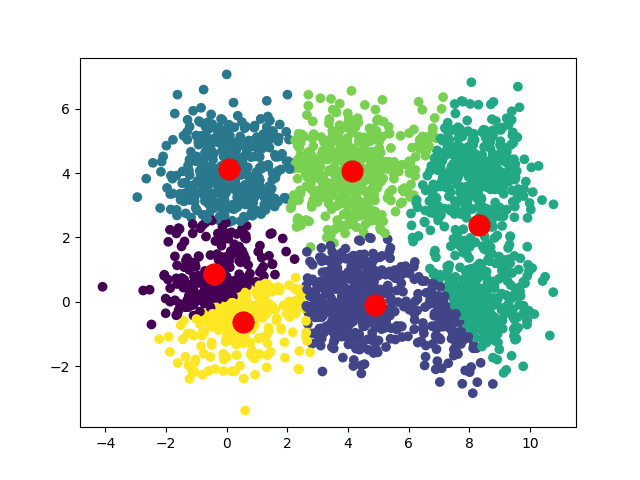
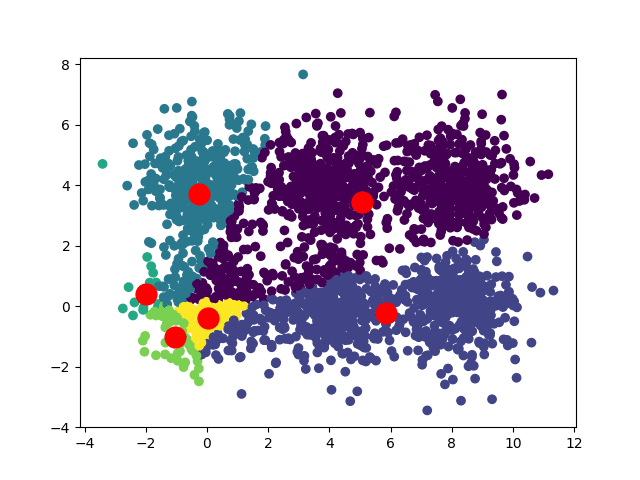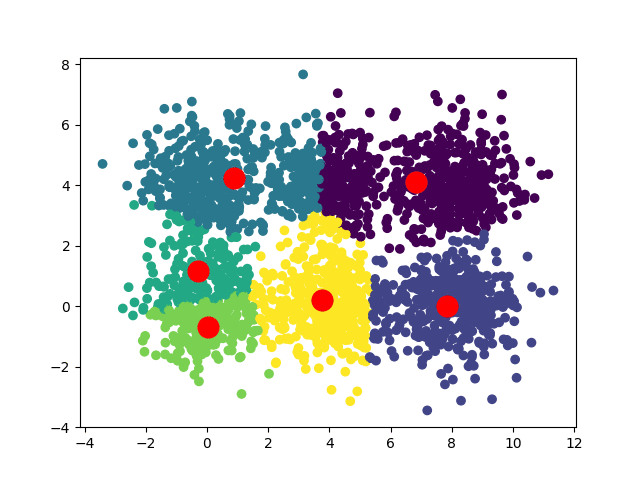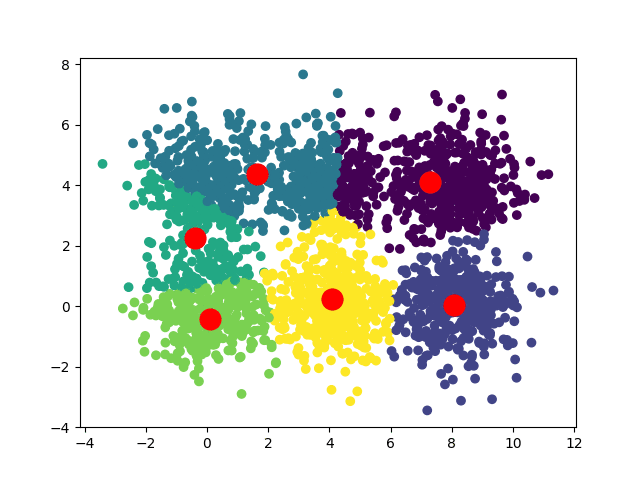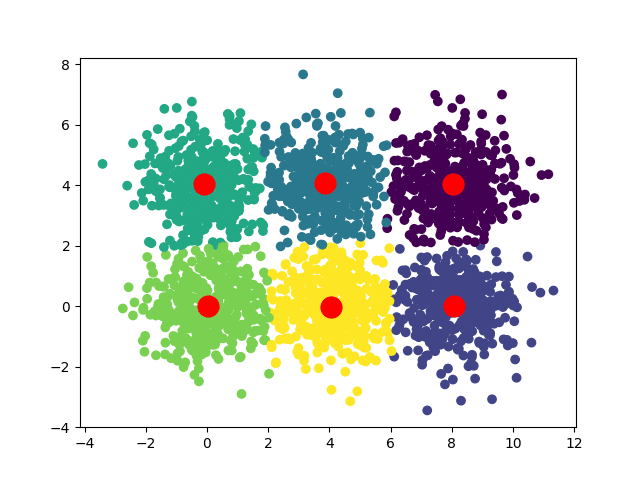
В случае квадратного набора данных мы можем иметь две сходимости:
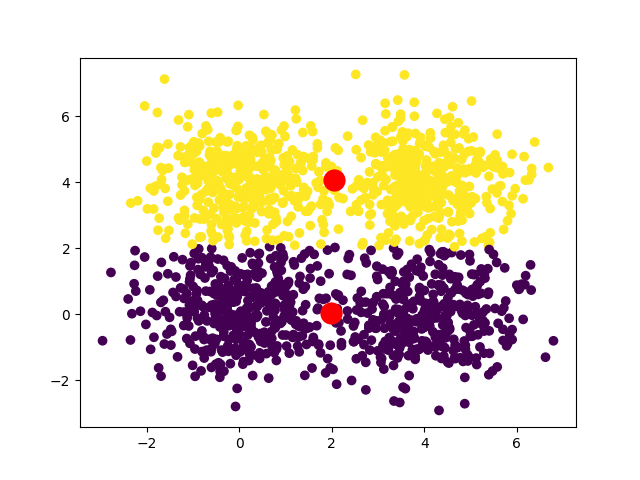
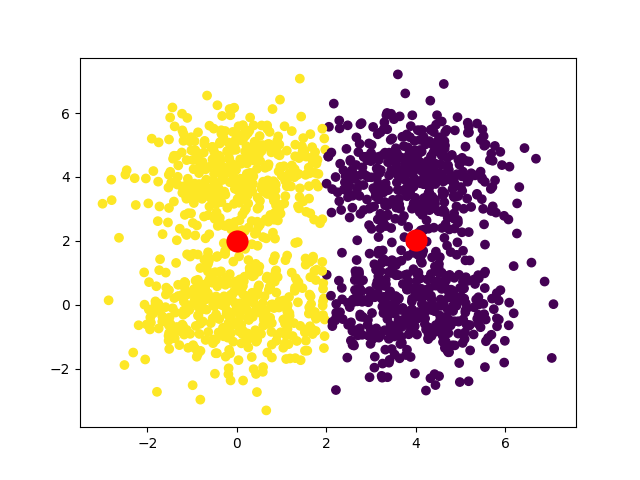
Если мы хотим получить уникальную сходимость, то интересным решением будет запустить алгоритм несколько раз, беря каждый раз разные начальные центроиды, и определить, какие результаты возвращаются чаще всего.
Сколько кластеров необходимо определить?
Первоначально алгоритм был написан для того, чтобы выдать k центроидов, зная k. Однако мы не всегда знаем это число k, поскольку оно зависит от формы, которую мы пытаемся анализировать.
Вот сходимости, наблюдаемые для k=3, k=4, k=5 и k=8
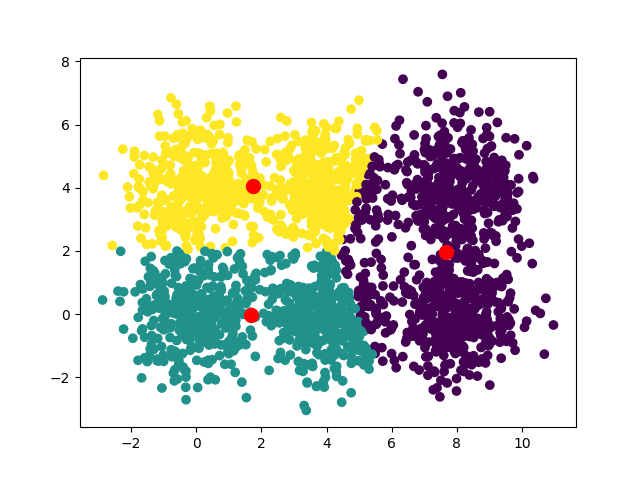
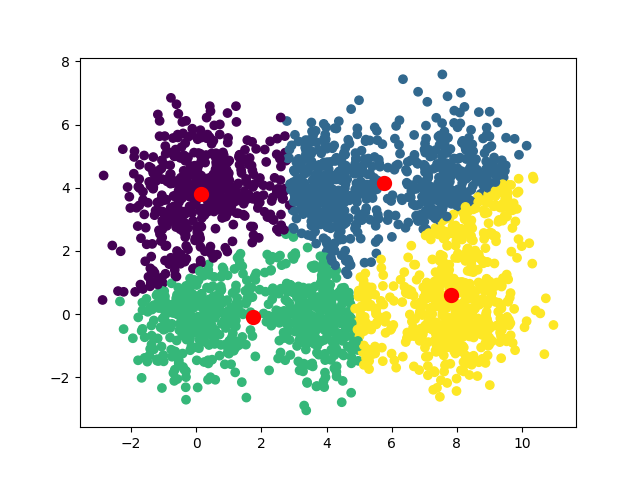
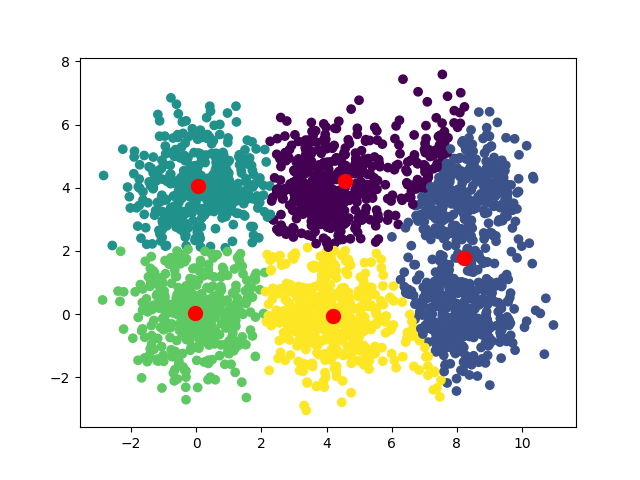
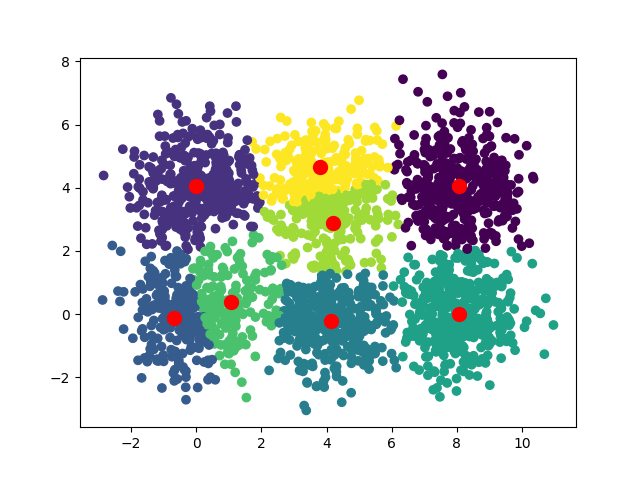
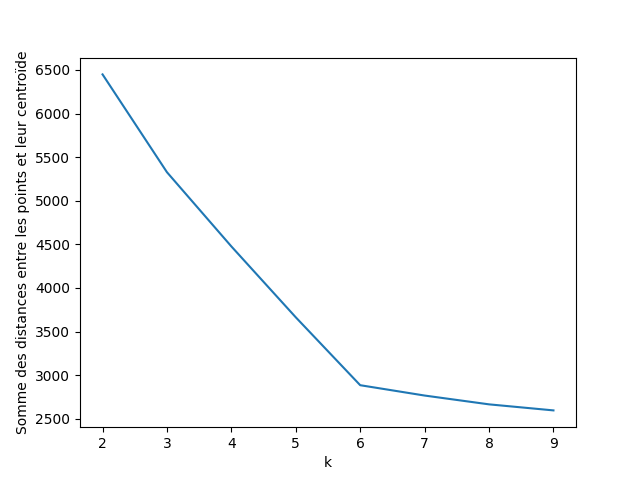
Одна из интересных идей – запустить алгоритм с различными значениями k и измерить для каждого из них сумму расстояний между точками и их центроидами. Используя технику перегиба, можно выделить оптимальное значение k. В нашем случае оптимальное значение равно 6, именно здесь график делает “перегиб”.
Заключение
В заключение можно сказать, что мы можем отметить этот алгоритм за его простоту в использовании и понимании.
Он сильно зависит от начальных положений центроидов и от используемой функции расстояния.
В нашем примере мы искали выпуклые кластеры (которые были похожи по евклидову расстоянию).
Если у вас вытянутые наборы, алгоритм k-средних может не дать хороших результатов.
Чтобы алгоритм k-средних был применим, ваши кластеры должны быть линейно разделяемыми.
Если у вас есть представление о форме ваших кластеров, вы можете попробовать переработать их заранее, чтобы сделать их более выпуклыми, в противном случае вам придется использовать другие алгоритмы разбиения данных.
