
 Автор:
Автор: Если DataFrame является основным типом данных библиотеки pandas, то очевидно, что главный навык, которым мы должны обладать при работе с этой библиотекой, заключается в том, как создавать DataFrame из данных.
Основная проблема заключается в том, что исходные данные обычно поступают в различных формах, будь то список, словарь, массив NumPy, обычный текстовый файл, файл CSV (значения, разделенные запятыми), файл JSON, база данных и так далее. В этой статье вы узнаете, как создать DataFrame из любого источника данных.
Для создания DataFrame используется функция-конструктор DataFrame(), которой предоставляется список или словарь с данными для ввода. Если данные находятся в файле или базе данных, вы должны использовать собственные функции, такие как read_csv, read_excel, read_json, read_html или read_sql.
Читайте дальше, чтобы получить общее представление о том, как генерировать DataFrame из любого источника данных. Я расскажу вам по порядку и приведу примеры, чтобы было понятно.
Содержание
- 1 DataFrame: таблица данных с маркированными строками и столбцами
- 2 Создание пустого DataFrame
- 3 Как добавить столбцы в DataFrame
- 4 Как вставить данные в DataFrame
- 5 Как создать DataFrame из массива
- 6 Как создать DataFrame из словаря
- 7 Как создать DataFrame из списка словарей
- 8 Как создать DataFrame из массива NumPy
- 9 Как создать DataFrame из файла CSV
- 10 Как создать DataFrame из данных буфера обмена
- 11 Как создать DataFrame из веб-страницы или HTML-файла
- 12 Как создать DataFrame из файла Excel
- 13 Как создать DataFrame из файла JSON
- 14 Как создать DataFrame из базы данных SQL
- 15 Как создать DataFrame из объектов pickle, parquet или Feather, файлов ORC, HDF, запросов SPSS, SAS, Stata или Google BigQuery.
- 16 Итоговая таблица
DataFrame: таблица данных с маркированными строками и столбцами
Прежде чем мы рассмотрим, как загружать различные источники данных в DataFrame, нам необходимо четко определить формат данных, который он представляет.
DataFrame представляет собой не что иное, как типичную двумерную таблицу данных со строками и столбцами. Кроме того, каждая строка и столбец могут иметь собственное имя или метку.
Так, например, мы можем сохранить в DataFrame расписание занятий, где столбцы – это дни, строки – часы, а значения – это каждый урок или предмет. Или мы можем также хранить список вылетов рейсов, где столбцы представляют номер рейса, время вылета и пункт назначения.
Обратите внимание, что таблица может иметь один столбец или одну строку, поэтому если вы встретите данные в таком формате, они также могут быть загружены в DataFrame. Они даже могут иметь одну строку и один столбец, т.е. одно значение!
Чтобы было понятнее, я приведу пример таблицы для наглядности моих слов:
| Имя | Возраст |
| Иван | 37 |
| Петр | 42 |
| Алексей | 40 |
Мы будем использовать таблицу, подобную этой, в некоторых примерах данной статьи.
Создание пустого DataFrame
Первая ситуация, в которой мы можем оказаться – это то, что мы должны создать DataFrame даже если у нас еще нет данных.
Лучшим вариантом для этого является создание пустого DataFrame. После создания мы можем добавлять в него данные, чтобы он постепенно рос.
Первое, что нужно понять, это то, что наш DataFrame будет экземпляром или объектом класса DataFrame библиотеки pandas. Поэтому мы будем использовать самый прямой способ создания объекта – с помощью его конструктора.
Убедитесь, что у вас установлена библиотека. Вы можете использовать команду pip install pandas.
В этом случае мы можем вызвать конструктор без каких-либо параметров, и у нас будет наш DataFrame, готовый принимать данные:
import pandas as pd
df = pd.DataFrame()Code language: JavaScript (javascript)Обратите внимание, что необходимо импортировать библиотеку, чтобы иметь возможность работать с ней. Мы также переименуем его в pd, чтобы получить более короткий код.
Прежде чем вводить данные, мы должны определить некоторые колонки, потому что не может быть таблицы без колонок.
Как добавить столбцы в DataFrame
Обратите внимание, что основным измерением DataFrame являются столбцы, поэтому доступ к столбцам всегда немного более прямой, чем к строкам. На самом деле, используя типичную скобочную нотацию, мы обращаемся к столбцам раньше, чем к строкам, что противоречит общепринятой практике.
Один из способов добавления нового столбца в DataFrame – присвоить ему непосредственно значения, которые должен иметь столбец, как это делается в словаре и в скобочной нотации. Поскольку в данном случае мы не хотим вводить значения, мы просто указываем None.
df['Name'] = None
print(df)Code language: PHP (php)В результате выполнения приведенного выше кода получается следующее, где видно, что в DataFrame, хотя он и пуст, появился новый столбец под названием Name. Кроме того, вы можете увидеть Index, но мы можем пока проигнорировать ее:
Empty DataFrame
Columns: [Name]
Index: []Code language: CSS (css)Другим способом добавления столбцов является использование функции assign в DataFrame. Эта функция позволяет нам добавлять колонки к уже созданным. Однако она не добавляет их в исходный DataFrame, а возвращает новый, содержащий новые плюс исходные столбцы:
df['Name'] = None
df = df.assign(Age=None)
print(df)Code language: PHP (php)Результатом выполнения приведенного выше кода будет:
Empty DataFrame
Columns: [Name, Age]
Index: []Code language: CSS (css)Будьте осторожны! Если вы назначите уже существующие колонки, вы перезапишете их значения. В данном случае это не имеет большого значения, потому что у нас пока нет данных, но имейте в виду, что они уже могут быть.
Итак, мы знаем, как добавить столбцы, но… вы согласитесь со мной, что от DataFrame без данных тоже мало толку. Давайте посмотрим, как добавить данные.
Как вставить данные в DataFrame
Когда у нас уже создан DataFrame со своими столбцами, нам остается только добавить в него данные. Существует несколько способов сделать это. Давайте посмотрим на некоторые из них.
Предположим, что у нас есть данные, которые нужно вставить в списки, то есть список для каждого столбца со значениями каждой строки для этого столбца. Мы можем сделать простое отображение следующим образом:
names = ['Иван', 'Петр', 'Алексей']
ages = [42, 40, 37]
df['Name'] = names
df['Age'] = ages
print(df)Code language: PHP (php)Результат этой операции будет следующим:
Name Age 0 Иван 42 1 Петр 40 2 Алексей 37
Будьте осторожны! Если вы присваиваете значения DataFrame таким образом, все списки должны иметь одинаковую длину.
Обратите внимание, что если вы присваиваете значения таким образом, вам не нужно предварительно создавать столбцы, так как присвоение само создает столбец, если он не был определен. Обратите внимание, что таким же образом вы можете смешивать старые значения с новыми, если колонка уже существует.
Когда у нас есть некоторые значения, мы можем добавить новые значения, вставляя полные строки. Это полезно, как я уже говорил, чтобы иметь возможность вставлять значения постепенно, по мере их получения или генерации. Для этого можно воспользоваться функцией append объектов DataFrame, которая добавляет строку в конец таблицы.
Вы можете предоставить этой функции объект типа Series of pandas, который представляет собой список значений, или объект типа dictionary, где каждое значение соответствует имени столбца в таблице в качестве ключа. Рассмотрим оба способа на одном примере:
names = ['Иван, 'Петртрр', 'Алексей']
ages = [42, 40, 37]
df['Name'] = names
df['Age'] = ages
new_row = { 'Name': 'Александр', 'Age': 29} # словарь
df = df.append(new_row, ignore_index=True)
new_row = pd.Series(['Аннанаа', 33], index=df.columns) # объект Series
df = df.append(new_row, ignore_index=True)
print(df)Code language: PHP (php)Обратите внимание на несколько моментов:
- Функция append возвращает новый объект с новыми значениями, поэтому мы должны выполнить присваивание df = df.append(…).
- Мы должны указать параметр ignore_index, установленный в False в функции append, чтобы она не учитывала индексы новых данных, которые могли бы быть указаны (хотя в данном случае они этого не делают). Помните, что мы можем добавить данные из другого DataFrame, у которого есть индексы.
- При создании объекта Series, помимо новых данных, необходимо указать столбцы (в том же порядке, что и данные). Для этого я использую параметр index и атрибут columns фрейма DataFrame, чтобы не писать их вручную.
Результатом приведенного выше кода является:
0 Иван 42 1 Петр 40 2 Алексей 37 3 Александр 29 4 Анна 33
Вы можете добавить сразу несколько строк, предоставив функции append список словарей или Series, по одному на строку. Это будет более эффективно, чем несколько вызовов функции, по одному вызову на строку.
Подобно столбцам, строки тоже могут иметь имя. Каждый ряд может иметь собственное название или метку. Вы можете представить себе еженедельный календарь, в котором каждая строка представляет собой день недели. Таким образом, мы можем обозначить каждый ряд названиями “понедельник”, “вторник”, “среда” и так далее.
Это делает очень удобным доступ к определенным строкам без необходимости знать их положение в таблице. Создадим DataFrame для хранения, например, лекарств, которые человек должен принимать утром, днем и вечером для каждого дня недели.
Другим способом добавления данных является использование атрибута loc фрейма DataFrame. loc позволяет получить доступ к определенной строке (или нескольким строкам) через ее имя.
Рассмотрим пример:
import pandas as pd
df = pd.DataFrame()
# создаем столбцы
df['Утро'] = None
df['Обед'] = None
df['Вечер'] = None
# добавляем строки по имени строки
df.loc['Понедельник'] = ['Витамины', 'Против алергии', 'Седативные']
df.loc['Вторник'] = ['Витамины', None, 'Против алергии']
df.loc['Среда'] = ['Седативные', 'Против алергии', 'Витамины']
print(df)Code language: PHP (php)Преимущество этой формы в том, что нам не нужно указывать имена столбцов для каждого значения. Однако необходимо указывать значения в соответствующем порядке. Результат получается следующим:
Утро Обед Вечер Понедельник Витамины Против аллергии Седативные Вторник Витамины None Против аллергии Среда Седативные Против аллергии Витамины
Обратите внимание, что во вторник во второй половине дня лекарств нет. В этом случае я могу указать значение None.
Это имена меток или строк, являющиеся набором индексов, которые print(df) намеревался вывести на экран, когда DataFrame был пуст.
Обратите внимание, что loc переписывает существующую строку в том случае, если указанный индекс уже существует в таблице.
Конечно, существует еще много способов вставки данных, но рассмотрение всех этих способов не является целью данной статьи, мы рассматриваем различные способы создания DataFrame. Теперь, когда мы увидели, как создать пустой и как создать еще один из значений столбцов, давайте рассмотрим другие способы.
Как создать DataFrame из массива
Если создание пустого DataFrame может быть первой идеей, которая приходит нам в голову, когда мы начинаем изучать pandas, то вторая идея – создать его из таблицы данных, уже созданной как массив.
Чтобы создать DataFrame из массива, называемого, например, data, просто вызовите конструктор, передав ему в качестве параметра список data следующим образом: DataFrame(data). Этот вызов вернет объект DataFrame, созданный с указанными данными и готовый к использованию.
Предположим, что у вас есть список из трех списков с четырьмя значениями в каждом, представляющий, например, следующую таблицу данных:
10 11 12 13 20 21 22 23 30 31 32 33
Давайте теперь создадим DataFrame из этого массива. Мы можем сделать следующее:
import pandas as pd
data = [[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33]]
df = pd.DataFrame(data)
print(df)Code language: JavaScript (javascript)Этот код генерирует вывод на экран, где видно, что по умолчанию имена столбцов равны 0, 1, 2 и 3, а имена строк – 0, 1 и 2.
0 1 2 3 0 10 11 12 13 1 20 21 22 23 2 30 31 32 33
Обратите внимание, что каждая строка в DataFrame соответствует каждой строке в исходном массива.
Если вы хотите, чтобы каждая строка в вашем списке списков стала столбцом в DataFrame, вам придется транспонировать DataFrame, то есть поменять строки на столбцы, при его создании, используя функцию transpose, как показано ниже df = pd.DataFrame(data).transpose().
Если вам нужны собственные имена столбцов, вы можете добавить параметр columns в вызов конструктора, чтобы перечислить имена столбцов.
Аналогично, если вы хотите дать имена строкам, вы можете сделать то же самое, но с параметром index:
import pandas as pd
data = [[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33]]
columns = ['C1', 'C2', 'C3', 'C4'] # определяем названия столбцов
rows = ['F1', 'F2', 'F3'] # определяем названия строк
df = pd.DataFrame(data, columns=columns, index=rows)
print(df)Code language: PHP (php)Таким образом, результат будет следующим:
C1 C2 C3 C4 F1 10 11 12 13 F2 20 21 22 23 F3 30 31 32 33
Как создать DataFrame из словаря
Другой распространенный случай – хранить данные каждого столбца нужной таблицы в словаре, помеченном именем столбца.
Чтобы создать DataFrame из словаря, просто предоставьте словарь конструктору класса DataFrame следующим образом: DataFrame(dictionary). Этот вызов возвращает объект DataFrame с данными из словаря, ключи которого являются именами столбцов.
Предположим, у вас есть словарь, в котором хранятся три списка, индексированные ключами Name, Age и Department. Вы просто предоставляете этот словарь конструктору DataFrame следующим образом:
import pandas as pd
data = {
'Name' : ['Иван', 'Петр', 'Алексей'],
'Age': [42, 40, 37],
'Department': ['Коммуникации', 'Администрация', 'Отдел продаж']
}
df = pd.DataFrame(data)
print(df)Code language: JavaScript (javascript)И это все! Вот так просто можно получить следующий результат:
Name Age Department 0 Иван 42 Коммуникации 1 Петр 40 Администрация 2 Алексей 37 Отдел продаж
Убедитесь, что все списки словарей имеют одинаковую длину.
Как создать DataFrame из списка словарей
Чтобы создать DataFrame из списка словарей, просто предоставьте список конструктору класса DataFrame следующим образом: DataFrame(list). Этот вызов возвращает объект DataFrame, содержащий данные списка с ключами в виде имен столбцов.
В данном случае пример выглядит следующим образом:
import pandas as pd
data = [
{'Name': 'Иван', 'Age': 42, 'Department': 'Коммуникации'},
{'Name': 'Петр', 'Age': 44, 'Department': 'Администрация'},
{'Name': 'Алексей', 'Age': 37, 'Department': 'Отдел продаж'}
]
df = pd.DataFrame(data)
print(df)Code language: JavaScript (javascript)Результатом приведенного выше кода будет:
Name Age Department 0 Иван 42 Коммуникации 1 Петр 40 Администрация 2 Алексей 37 Отдел продаж
Основная проблема этого решения заключается в том, что вы должны убедиться, что ключи в каждом словаре корректны и согласованы друг с другом. В целевом DataFrame будет создано столько столбцов, сколько различных ключей в словарях. Если, например, ключ, связанный с именем, в одном словаре – Name, в другом – name, а в третьем – NAME, то в итоге мы получим три разных колонки (с учетом регистра) для данных об имени, что нам не нужно. Кроме того, у нас будет много значений None, потому что если в других словарях нет значений для определенного ключа, то по умолчанию у нас будет именно None.
Как создать DataFrame из массива NumPy
Часто бывает, что данные, которые нам нужно обработать как DataFrame, хранятся в массиве NumPy.
Чтобы создать DataFrame из массива NumPy, необходимо вызвать конструктор DataFrame, снабдив его таким массивом следующим образом: DataFrame(array). Если мы хотим указать имена столбцов, они должны быть указаны в параметре columns.
В данном случае все очень просто.
Перед созданием DataFrame мы создадим массив NumPy (убедитесь, что у вас установлена библиотека numpy):
import pandas as pd
import numpy as np
array = np.array([
[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33]
])
columns = ['C1', 'C2', 'C3', 'C4'] # этот список также может быть массивом NumPy
df = pd.DataFrame(array, columns = columns)
print(df)Code language: PHP (php)В результате, где каждая строка массива соответствует строке DataFrame, получается:
C1 C2 C3 C4 0 10 11 12 13 1 20 21 22 23 2 30 31 32 33
Как создать DataFrame из файла CSV
Часто мы храним данные в CSV-файле (Comma Separated Values), который представляет собой не что иное, как текстовый файл в виде таблицы, где значения разделены запятыми (или другим символом). Кроме того, эти файлы обычно имеют первую строку, которая выступает в качестве заголовка с названиями столбцов.
Для создания DataFrame из значений файла CSV можно использовать функции pandas read_csv или read_table, указав им файл и символ разделителя. Эти функции создают новый DataFrame с данными, содержащимися в файле.
Предположим, что у нас есть текстовый файл data.csv, который имеет следующее содержание:
Name, Age, Department Иван, 42, Коммуникации Петр, 40, Администрация Алексей, 37, Отдел продаж
Это данные, из которых мы создадим DataFrame.
Один из вариантов – использовать функцию read_csv, которая представляет собой функцию, специально разработанную для чтения файлов CSV. Он имеет множество параметров, но для простых файлов нам нужно указать только имя файла и символ, который используется в этом файле в качестве разделителя. В данном случае таким символом является запятая.
Рассмотрим пример:
import pandas as pd
df = pd.read_csv('data.csv', delimiter=',') # вы также можете использовать функцию read_table
print(df)Code language: PHP (php)Результат на экране будет выглядеть следующим образом:
Name Age Department 0 Иван 42 Коммуникации 1 Петр 40 Администрация 2 Алексей 37 Отдел продаж
В этом простом случае вы можете использовать функцию read_table аналогичным образом, и результат будет таким же.
Если файл для чтения приходит без имен колонок, мы должны указать их через параметр names следующим образом: pd.read_csv(‘data.csv’, delimiter=’,’, names=[‘Name’,’Age’,’Department’]). Если нам не нужны имена столбцов, мы можем задать параметр header=None.
Еще одна функция, похожая на те, которые я только что представил, это read_fwf, которая генерирует таблицу данных из текстового файла, где поля имеют фиксированную ширину, поэтому нет необходимости использовать символ-разделитель, но операция очень похожа.
Как создать DataFrame из данных буфера обмена
Если у вас есть данные в формате таблицы, подобном предыдущему случаю, разделенные запятыми (или другим разделителем) в системном буфере обмена, pandas позволяет читать их прямо оттуда без необходимости создавать для этого файл. Это интересно, поскольку позволяет нам динамически и очень быстро создавать DataFrame из данных, полученных из различных источников, просто копируя данные в буфер обмена.
Для создания DataFrame из значений, разделенных запятыми, скопированных в системный буфер обмена, можно использовать функцию pandas read_clipboard, указав символ-разделитель. Эта функция создает новый DataFrame с данными, содержащимися в буфере обмена.
Попробуйте это сделать, выбрав данные из следующего примера и скопировав их:
Name, Age, Department Иван, 42, Коммуникации Петр, 40, Администрация Алексей, 37, Отдел продаж
Теперь просто используйте функцию read_clipboard, и у вас есть DataFrame – почти магия!
import pandas as pd
df = pd.read_clipboard(',')
print(df)Code language: JavaScript (javascript)Результат будет таким же, как и выше.
Если символ-разделитель полей не является одним или несколькими пробелами, вы должны указать нужный символ или строку, передав параметр функции, например, read_clipboard(‘,’). Если вы вызываете функцию без параметров, в качестве разделителей будут использоваться пробелы.
Как создать DataFrame из веб-страницы или HTML-файла
Если мы хотим получить данные из HTML-таблицы файла или веб-страницы, pandas упрощает задачу. Да, даже в этом случае, который может показаться сложнее.
Для создания DataFrame из таблиц веб-страницы или HTML-файла можно использовать функцию pandas read_html, указав файл или URL для чтения. Эта функция ищет теги и создает список DataFrames с каждой из таблиц в документе.
Функция read_html ищет теги <table> и элементы <tr> (строка), <th> (заголовок) и <td> (данные) и генерирует DataFrame для каждой из найденных таблиц, поэтому она всегда возвращает список со сгенерированными DataFrame.
Помните обо всех проблемах, связанных с разбором и чтением веб-страниц. Скорее всего, придется выполнить некоторую очистку ваших DataFrames после чтения.
Нам понадобится библиотека lxml, которая используется для обработки и разбора XML и HTML файлов в Python. Убедитесь, что вы установили его с помощью команды pip install lxml.
Ниже приведен небольшой HTML-файл, который я создал с двумя различными таблицами и назвал data.html.
<html>
<head>
<meta charset="UTF-8">
<title>Тестовая страница с таблицами HTML</title>
</head>
<body>
<h1>Как создать DataFrames из файлов HTML<h1>
<h2>Таблица 1</h2>
<table>
<tr>
<th>Name</th>
<th>Age</th>
</tr>
<tr>
<td>Иван</td>
<td>42</td>
</tr>
<tr>
<td>Петр</td>
<td>40</td>
</tr>
<tr>
<td>Алексей</td>
<td>37</td>
</tr>
</table>
<h2>Таблица 2</h2>
<table>
<tr>
<th>A</th>
<th>B</th>
<th>C</th>
</tr>
<tr>
<td>4</td>
<td>4</td>
<td>3</td>
</tr>
<tr>
<td>5</td>
<td>9</td>
<td>0</td>
</tr>
<tr>
<td>6</td>
<td>5</td>
<td>2</td>
</tr>
<tr>
<td>0</td>
<td>6</td>
<td>3</td>
</tr>
<tr>
<td>9</td>
<td>1</td>
<td>8</td>
</tr>
</table>
</body>
</html>Code language: HTML, XML (xml)С этим документом, который вы можете скопировать и вставить в пустой файл, мы выполним следующий пример. Вы можете открыть HTML-файл с помощью веб-браузера, чтобы увидеть его содержимое и созданные таблицы. В примере создается список DataFrame с двумя объектами, по одному для каждой таблицы в HTML-документе. Затем этот список выводится на экран:
import pandas as pd
dfs = pd.read_html('data.html')
for df in dfs:
print(df, '\n')Code language: JavaScript (javascript)Результат, который мы получаем, следующий:
Name Age 0 Иван 42 1 Петр 40 2 Алексей 37 A B C 0 4 4 3 1 5 9 0 2 6 5 2 3 0 6 3 4 9 1 8
Возможно, что из-за различных факторов чтение с помощью библиотеки lxml может быть неудачным, в этом случае будут использоваться библиотеки html5lib или bs4, которые у вас также должны быть установлены. Если вы предпочитаете, чтобы чтение выполнялось непосредственно с этими библиотеками, вы можете задать функции параметр flavor=’bs4′.
Как создать DataFrame из файла Excel
Другим распространенным случаем является наличие данных в файле Microsoft Excel или в совместимой электронной таблице, например, в таблицах открытого формата из пакета LibreOffice.
Чтобы создать DataFrame из электронной таблицы или файла Excel, вы можете использовать функцию pandas read_excel, указав ей имя файла. Эта функция открывает и считывает файл и создает DataFrame с его содержимым, готовый к использованию.
На изображении ниже показаны данные, содержащиеся в электронной таблице, в данном случае созданной с помощью Google Drive и сохраненной в формате xlsx с именем data.xlsx.
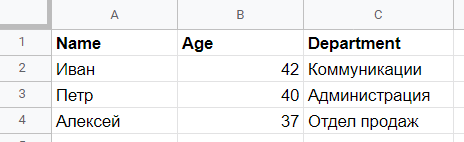
Для загрузки данных из файла и создания DataFrame мы будем использовать функцию read_excel. Эта функция выполняет чтение данных из исходного файла с помощью другой библиотеки. Так как в данном случае формат файла – Excel, используемая библиотека – openpyxl, которую необходимо установить с помощью команды pip install openpyxl. Если нам нужно прочитать файл в формате Open Document Format (например, в LibreOffice), то библиотека для установки – odf.
После установки необходимой библиотеки мы можем использовать функцию read_excel следующим простым способом:
import pandas as pd
df = pd.read_excel('data.xlsx')
print(df)Code language: JavaScript (javascript)Легко, не так ли? Результат на экране будет выглядеть следующим образом:
Name Age Department 0 Иван 42 Коммуникации 1 Петр 40 Администрация 2 Алексей 37 Отдел продаж
Может случиться так, что таблица, которую мы хотим прочитать, находится в определенной строке и столбце файла. В этом случае нам придется указать ему, какие строки игнорировать с помощью параметра skiprows и какие столбцы читать с помощью параметра usecols.
Также возможно, что таблица, которую нам нужно загрузить, находится не на первом листе документа. Мы можем использовать параметр sheet_name для указания листа, на котором он должен искать данные. Мы можем указать номер листа, учитывая, что первый из них – 0, или название листа.
Например, если таблица данных начинается со строки 3 и столбца B листа с названием Employees в файле data.xlsx, мы можем загрузить данные следующим образом: df = pd.read_excel(‘data.xlsx’, sheet_name=’Employees’, usecols=’B:D’, skiprows=2).
Как создать DataFrame из файла JSON
Другой вариант – хранить данные в файле JSON, что очень популярно в настоящее время.
Для создания DataFrame из файла JSON можно использовать функцию pandas read_json, задав ей имя файла следующим образом pandas.read_jason(‘data.json’). Эта функция создает новый DataFrame с данными, содержащимися в предоставленном файле.
Создадим DataFrame с теми же данными, что и в предыдущих примерах, только в этом случае исходный файл будет в формате JSON:
[
{
"Name": "Иван",
"Age": 42,
"Department": "Коммуникации"
},
{
"Name": "Петр",
"Age": 40,
"Department": "Администрация"
},
{
"Name": "Алексей",
"Age": 37,
"Department": "Отдел продаж"
}
]Code language: JSON / JSON with Comments (json)Теперь вам остается только использовать функцию read_json, которая будет считывать данные из файла и создавать DataFrame:
import pandas as pd
df = pd.read_json('data.json')
print(df)Code language: JavaScript (javascript)И чтобы не повторяться, результат будет таким же, как и в предыдущих случаях.
Как создать DataFrame из базы данных SQL
Давайте рассмотрим немного более сложный пример, использующий возможности баз данных SQL.
Для создания DataFrame из базы данных SQL можно использовать функцию pandas read_sql, которой необходимо предоставить имя таблицы или SQL-запрос и соединение с базой данных. Функция вернет DataFrame с соответствующими данными, готовый к использованию.
Предположим, что на этот раз у нас есть две разные таблицы в базе данных. Одна из сотрудников и одна из отделов. Таблица сотрудников содержит такие столбцы, как код сотрудника, имя, возраст и код отдела, в котором работает сотрудник. Таблица отдела имеет в качестве столбцов код отдела, название и местоположение.
Мы хотим создать DataFrame, в котором будут столбцы обеих таблиц, которые мы должны объединить с помощью операции объединения в столбце кода отдела.
В вашем случае база данных уже создана в определенной системе управления базами данных, такой как MariaDB или PostgreSQL. В этом примере я буду работать с SQLite.
Убедитесь, что у вас установлена библиотека SQLAlchemy, поскольку она необходима pandas для подключения к базе данных. Вы можете установить его с помощью команды pip install sqlalchemy.
Я создал базу данных под названием database_base.db (оригинально, не правда ли?) со структурой, которую я описал выше. Я также вставил некоторые данные в эти две таблицы. Я оставляю здесь SQL-код, позволяющий создать базу данных в точности как у меня, так что вы можете попробовать этот пример, если вам интересно:
BEGIN TRANSACTION;
CREATE TABLE IF NOT EXISTS "employees" (
"code" INTEGER NOT NULL,
"name" TEXT,
"age" INTEGER,
"department" INTEGER,
PRIMARY KEY("code" AUTOINCREMENT)
);
CREATE TABLE IF NOT EXISTS "departments" (
"code" INTEGER NOT NULL,
"name" TEXT,
"location" TEXT,
PRIMARY KEY("code" AUTOINCREMENT)
);
INSERT INTO "employees" VALUES (1,'Иван',42,1);
INSERT INTO "employees" VALUES (2,'Петр',40,2);
INSERT INTO "employees" VALUES (3,'Алексей',37,3);
INSERT INTO "employees" VALUES (4,'Анна',29,2);
INSERT INTO "employees" VALUES (5,'Мария',32,3);
INSERT INTO "departments" VALUES (1,'Коммуникации','Первый этаж');
INSERT INTO "departments" VALUES (2,'Администрация','Второй этаж');
INSERT INTO "departments" VALUES (3,'Отдел продаж','Первый этаж');
COMMIT;Code language: PHP (php)После создания базы данных нам остается только создать несколько DataFrames. Начнем с самого прямого варианта, который заключается в загрузке DataFrame с каждой из таблиц.
Для этого нам просто нужно использовать функцию read_sql, которой мы должны передать два параметра. Первое – это имя таблицы, которую мы хотим прочитать. Второй – это строка подключения к базе данных, которая в нашем случае будет в стиле sqlite:///database_name.db. Мы это видим:
import pandas as pd
df_employees = pd.read_sql('employees', 'sqlite:///database_base.db')
df_departments = pd.read_sql('departments', 'sqlite:///database_base.db')
print('Сотрудники:', df_employees, sep='\n')
print('Отделы:', df_departments, sep='\n')Code language: PHP (php)Если вы заметили, теперь у нас есть два DataFrames, это df_employees и df_departments. Когда мы выводим их на экран, то получаем следующее:
Сотрудники: code name age department 0 1 Иван 42 1 1 2 Петр 40 2 2 3 Алексей 37 3 3 4 Анна 29 2 4 5 Мария 32 3 Отделы: code name location 0 1 Коммуникации Первый этаж 1 2 Администрация Второй этаж 2 3 Отдел продаж Первый этаж
Так просто и так быстро. Но теперь давайте сделаем кое-что более сложное, потому что я хочу получить один DataFrame со всеми полями обеих таблиц, объединенными так, чтобы за каждым сотрудником следовала информация его отдела, а не только его код.
Я могу решить это с помощью простой операции объединения между двумя таблицами, которую можно выполнить следующим образом, где я также выбираю только некоторые поля, потому что меня не интересуют коды. SQL-запрос выглядит следующим образом:
select e.name, e.age, d.name as department, d.location
from employees as e inner join departments as d
on e.department = d.code;Code language: JavaScript (javascript)Сила функции read_sql заключается в том, что она позволяет нам задать SQL-запрос для получения нужных нам данных и затем как можно меньше манипулировать DataFrame. Просто введите запрос вместо имени таблицы, и все готово. Код:
import pandas as pd
query = '''
select e.name, e.age, d.name as department, d.location
from employees as e inner join departments as d
on e.department = d.code;
'''
df = pd.read_sql(query, 'sqlite:///database_base.db')
print(df)Code language: PHP (php)Результат следующий:
name age department location 0 Иван 42 Коммуникации Первый этаж 1 Петр 40 Администрация Второй этаж 2 Алексей 37 Отдел продаж Первый этаж 3 Анна 29 Администрация Второй этаж 4 Мария 32 Отдел продаж Первый этаж
Как создать DataFrame из объектов pickle, parquet или Feather, файлов ORC, HDF, запросов SPSS, SAS, Stata или Google BigQuery.
Существуют и другие менее распространенные или более специализированные объекты или файлы данных, из которых также может быть сгенерирован DataFrame.
Если вы прочитали часть этой статьи, вы уже поняли общий подход к созданию DataFrame. Поэтому я не буду приводить примеры всех этих форматов, потому что статья будет слишком длинной (а я думаю, что она и так слишком длинная), но я хочу дать вам список функций, используемых для чтения этих объектов и файлов, чтобы вы знали об их существовании.
Со всеми этими функциями, а также со всеми теми, о которых я уже рассказал, можно ознакомиться в официальной документации pandas.
| Объект или файл | Функция |
| Pickle | read_pickle |
| PyTables, HDF5 | read_hdf |
| Feather | read_feather |
| Parquet | read_parquet |
| ORC | read_orc |
| SAS | read_sas |
| SPSS | read_spss |
| Google BigQuery | read_gbq |
| Stata | read_stata |
Итоговая таблица
Мы рассмотрели несколько способов создания DataFrame с помощью pandas и Python. Если вы прочитали всю статью, то увидели, что все способы очень похожи, хотя каждый из них имеет свои особенности. Идея здесь в том, что пандас хочет сделать нашу жизнь проще, как вы видите.
В качестве резюме я привожу здесь таблицу со всеми рассмотренными нами способами и функциями для создания DataFrame.
| Источник данных | Пример |
| Данные отсутствуют | df = pd.DataFrame(columns=['Столбец 1', 'Столбец 2'])df['Столбец 3'] = Nonedf['Столбец 4'] = None |
| Список списков, список словарей | df = pd.DataFrame(list) |
| Словарь списков | df = pd.DataFrame(dictionary) |
| Массив NumPy | df = pd.DataFrame(array) |
| Формат CSV | df = pd.read_csv('data.csv')df = pd.read_table('data.csv', delimiter=',') |
| Файл с полями поля фиксированной ширины | df = pd.read_fwf(‘data.fwf’) |
| Данные в буфере обмена | df = pd.read_clipboard() |
| Веб-файлы или файлы HTML | dfs = pd.read_html('data.html')dfs = pd.read_html(url) |
| Электронная таблица | df = pd.read_excel(‘data.xlsx’) |
| JSON-файл | df = pd.read_json(‘data.json’) |
| База данных SQL | df = pd.read_sql(table, connection_bd)df = pd.read_sql(query, connection_bd) |
| Другие форматы | См. таблицу 2 |
