
 Автор:
Автор: Есть ли у вас такой друг, который иногда снимает пиджак, протягивает его вам и говорит: “Пока-пока, что происходит!”? Да. Все заканчивается по-другому. Иногда смешные, иногда замечательные, иногда на скорую руку. Это что-то вроде модели машинного обучения, только другое…
В предыдущем эпизоде, где речь шла больше о теории, я анонсировал более практический пост, который покажет, как начать работу с машинным обучением. Только через 7 месяцев я могу с гордостью сказать: “Вот он я”. Здесь, пожалуйста, обратите внимание, что мне понадобилось всего 7 месяцев, в то время как, например, Джордж Р.Р. Мартин писал “Песнь льда и пламени” пять лет. Также вы можете увидеть, насколько я вынослив!
Прочитав эту заметку, которая повторяет шаги, представленные в предыдущей заметке, вы узнаете, как на практике обучить модель машинного обучения. На самом деле, вы не только будете учиться, но и обучать модель машинного обучения!
Содержание
- 1 Окружающая среда
- 2 Определение проблемы и сбор данных
- 2.1 Давайте определим проблему
- 2.2 Где мы получаем данные?
- 2.3 Какую проблему мы решаем. Классификация? Регрессия? Кластеризация?
- 2.4 Выбранная нами метрика должна соответствовать обозначенной нами проблеме.
- 2.5 Качество и количество данных – от этого зависит, насколько качественная модель может быть создана
- 3 Подготовка, очистка данных
- 4 Выбор модели
- 5 Обучение
- 6 Оценка
- 7 Оптимизация гиперпараметров
- 8 Предсказания
Окружающая среда
Язык – Python
Мы будем использовать язык Python. Если вы никогда не имели с ним дела, это первый инструмент, который вы должны изучить, прежде чем войти в мир машинного обучения. Но прежде чем вы броситесь смотреть курсы на Udemy , постарайтесь прочесть этот пост.
Python – довольно забавный язык для чтения. Если в прошлом вы имели дело с любым другим языком программирования, вы легко сможете понять представленный здесь код.
IDE – Jupyter Notebook
Чтобы избежать хлопот с подготовкой всей среды, мы воспользуемся самым быстрым и простым решением.
В мире машинного обучения очень широко используются блокноты Jupyter Notebook. Если вы еще не знаете, что это такое, загляните в Jupyter Notebook QuickStart. Блокнот будет нашим основным инструментом, используемым для “игры” с кодом.
Окружающая среда – Google Colab
Как я уже говорил, чтобы не настраивать все самостоятельно, мы будем использовать Google Colab – бесплатную платформу, которая позволяет работать с Python в блокнотах и запускать код. Python – интерпретируемый язык, поэтому мы можем запускать отдельные ячейки кода независимо друг от друга. Более того, в Google Colab у нас есть доступ к графической карте (GPU), что может ускорить процесс в X раз при обучении моделей.
Анализ данных Pandas
Для добычи данных мы будем использовать библиотеку Pandas. Pandas – это хорошо известный в сообществе data science инструмент, позволяющий быстро и гибко манипулировать наборами данных.
Создание модели – FAST.AI
Мы создадим модель машинного обучения с помощью библиотеки fast.ai. Fast.ai делает процесс обучения моделей очень простым и с очень хорошими результатами.
Это наша первая модель, поэтому давайте начнем как можно проще. Давайте следовать духу, который пропагандирует Джереми Ховард – один из создателей библиотеки Fast.AI
Определение проблемы и сбор данных
С чего лучше всего начать? Давайте обучим модель машинного обучения для решения проблемы. Что за проблема?
Давайте определим проблему
Предположим, мы химики-алкоголики. Или нет. Наш друг, Вася, химик-алкоголик. Вернись! Знаток вина. Он хотел бы попробовать свои силы в любительском виноделии. Поскольку Вася – химик, он может измерить ряд параметров производимого им напитка. Более того, как знаток, он может отнести вино к одному из трех классов. Пока мы не уточняем, какие это классы. Мы предполагаем, что наш коллега знает, что делает.
Мы хотели бы избавить Васю от необходимости “пробовать” каждое вино, которое он делает. Поэтому мы построим модель машинного обучения, которая, основываясь на химических данных, отнесет вино к одному из 3 классов. Таким образом, вина будут распределены по категориям, и Вася будет в большей безопасности.
Где мы получаем данные?
Наш коллега также является уважаемым ученым, поэтому его работа была опубликована на сайте Калифорнийского университета в Ирвайне (UCI). По крайней мере, он так утверждает. Оттуда мы их и загрузим.
import requests
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data'
data_file = open("./wine.data", "wb").write(requests.get(url).content)Code language: JavaScript (javascript)Отвлекусь: страницу репозитория UCI Machine Learning Repository стоит добавить в закладки – она содержит множество различных наборов данных, которые можно использовать для обучения, тестирования, попыток. Рекомендую, наслаждайтесь!
Какую проблему мы решаем. Классификация? Регрессия? Кластеризация?
Фактически, мы ответили на этот вопрос, правильно определив проблему. Мы хотим отнести каждое вино, произведенное и изученное Васей, к одному из трех классов: 1, 2 или 3 (пока неважно, что они означают – доверьтесь Васе).
Здесь мы имеем дело с проблемой (помимо алкоголизма коллеги, конечно) многоклассовой классификации (multiclass classification).
Если посмотреть на вышеизложенное, то модель машинного обучения, которую мы хотим создать, это… Да, именно, классификатор!
Выбранная нами метрика должна соответствовать обозначенной нами проблеме.
Мы относим вино к одному из 3 классов. В случае такой задачи мы можем использовать, например, эффективность (точность). Мы проверяем, сколько вин мы правильно присвоили классу. На данный момент нам будет достаточно этой простой метрики.
Эффективность – это та метрика, которую мы будем оптимизировать – мы постараемся сделать ее как можно более высокой. В проекте машинного обучения можно также задать “удовлетворительные” метрики, то есть метрики, которые нам нужно удовлетворить, но они не являются целью оптимизации. Примером может быть:
- вся модель должна занимать менее 20 МБ памяти
- предсказание для одной выборки данных должно занимать меньше времени, чем требуется Васе, чтобы опорожнить свой стакан
Все, что нам нужно, – это достичь заданных результатов, а из всех моделей, которые им соответствуют, мы выбираем ту, у которой самая высокая метрика, которую мы оптимизируем.
Это всего лишь примеры. В нашем случае мы боремся только за эффективность. Давайте сражаться! Давайте посмотрим на данные.
Качество и количество данных – от этого зависит, насколько качественная модель может быть создана
Когда мы смотрим на файл данных, мы видим, что у нас 178 образцов. Скажем так, именно столько нам удалось собрать, пока наш коллега-химик не сказал, что с него хватит.
А как насчет их качества? Пока что у нас есть данные Шредингера. Позволят ли они нам обучить модель?
Подготовка, очистка данных
В документации мы можем прочитать, что эта коллекция содержит следующую информацию о каждом вине:
- Category
- Alcohol
- Malic acid
- Ash
- Alcalinity of ash
- Magnesium
- Total phenols
- Flavanoids
- Nonflavanoid phenols
- Proanthocyanins
- Color intensity
- Hue
- OD280/OD315 of diluted wines
- Proline
Что это за колонки? Понятия не имею. Вася знает, но утверждает, что если он расскажет, то ему придется меня убить. Но с уверенностью в голосе он заявляет, что это все данные, которые ему нужны, и все они одинаково важны. У него нет времени на глупости, поэтому все, что он делает, имеет смысл.
Мэтью, я доверяю тебе. Итак, давайте посмотрим на данные.
Теперь мы можем использовать Pandas. Как загрузить данные из файла CSV в Pandas? Более конкретно, как загрузить данные из файла CSV в DataFrame, структуру, которую мы используем в Pandas для табличных данных? Ну, с помощью метода read_csv(), которому мы передадим путь к файлу и одновременно сообщим, что первая строка не содержит заголовка, следовательно, имена столбцов должны быть взяты из переменной attributes.
df = pd.read_csv("wine.data", header=None, names=attributes)Code language: JavaScript (javascript)Анализ данных
Мы должны детально, глубоко и тщательно изучить данные, которые будем использовать для создания модели машинного обучения. Какие вопросы мы можем задать себе?
Сбалансированы ли данные?
Как мы это узнаем? Нам нужно подсчитать, сколько образцов у нас есть для каждого класса. В Pandas для этого мы можем использовать метод value_counts() для столбца категорий. Эта функция подсчитывает количество вхождений каждого уникального значения в столбец.
df['category'] \ # для столбца с ассоциированными классами
.value_counts() \ # подсчитаем уникальные значения
.sort_index() \ # Давайте сделаем так, чтобы было красиво.
.plot.bar() # и построим графикCode language: CSS (css)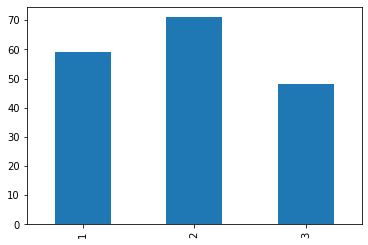
Если закрыть на это глаза, то можно сказать, что классы достаточно сбалансированы. Особенно после долгих обсуждений с Васей. Что дальше?
Нормализация?
Давайте начнем с честного ответа: что такое нормализация данных?
Нормализация данных обычно означает масштабирование значений таким образом, чтобы они находились в интервале [0, 1].
Как и в жизни – есть положительные плюсы и отрицательные плюсы. При нормализации мы оперируем положительными значениями той же шкалы, но теряем информацию о выбросах.
В библиотеке fast.ai эта операция очень проста. Просто добавьте импортированный метод Normalize в список методов, используемых в препроцессинге. В нашем случае это выглядит следующим образом:
preprocessing_steps = [Normalize]
Действительно ли нам нужно точное значение в столбце, или мы можем сгруппировать данные каким-либо образом?
В чем здесь дело?
Если бы у нас были данные о компаниях, можно было бы создать столбец “Местонахождение”, в котором были бы географические координаты штаб-квартиры этой компании. Нужны ли нам точные координаты для обучения модели? Возможно, но мы можем заменить этот столбец столбцами county, city, district.
В нашем случае мы имеем дело со значениями измерений. Как правило, это непрерывные величины. На этот раз оставим столбцы такими, какие они есть. Как гласит старая индийская пословица:
Если работает, не трогай.
Есть ли у нас вообще все необходимые функции? Достаточно ли того, что у нас есть, или нам нужен более широкий контекст?
На данный момент мы не можем получить больше возможностей от нашего коллеги (у него есть более важные дела), поэтому мы продолжаем работать с тем, что у нас есть, надеясь, что этого будет достаточно.
Разбивка на комплекты
Мы чисты. На самом деле, наши данные чисты. Очищено в меру наших сил и знаний. Теперь настало время для следующего шага. Давайте разделим наш набор данных на подмножества:
- Тренировка
- Валидация / тестирование
Мы будем использовать первые для обучения модели, а вторые – для проверки ее эффективности.
Нам нужно проверить модель на данных, которые мы не использовали для обучения.
Почему мы не разделяем валидационный и тестовый наборы? У нас очень мало данных – 178 образцов. При таких небольших данных разбиение набора на 3 подмножества еще больше ограничило бы количество данных для обучения. Кроме того – мы просто практикуем 😉 Более подробный ответ вы можете прочитать здесь и здесь.
Отступление: В случае небольших данных можно использовать технику перекрестной валидации. Пока, однако, давайте останемся с классическим разделением.
Давайте вернемся на наш задний двор. В fast.ai для метода обучения мы задаем список индексов строк, которые должны быть в валидационном множестве. Давайте подготовим такой список! В нашем случае пусть это будет 25% от всего набора данных.
# посмотрим, сколько 25%
valid_count = int(len(df) * 0.25)
# перемешаем строки в таблице
df = df.sample(frac=1).reset_index(drop=True)
# и сохраним идентификатор нижних 25% записей.
valid_idx = range(len(df) - valid_count, len(df))Code language: PHP (php)Выбор модели
У нас есть данные! Наступает прекрасный момент, когда мы можем заняться машинным обучением, а не какими-то NaN, пустыми строками и отсутствующими столбцами. Так давайте научим модель! Но какой?
Как я уже упоминал в предыдущем посте, существует множество различных моделей, придуманных умными людьми.
В библиотеке fast.ai разработчики сделали акцент на том, чтобы сделать модели как можно более простыми. В настоящее время на вершине находятся нейронные сети, поэтому они сделали реализации популярных сетей, готовые к использованию и обучению.
В этом случае нам даже не нужно напряженно думать о том, какую сеть использовать. Мы создаем объект Learner и обучаем его. Для “табличных” данных, как в нашем случае, подойдет TabularModel. Чтобы сделать это еще проще, мы будем использовать метод tabular_learner(), который автоматически создаст для нас TabularModel.
Обучающему устройству мы передаем наши данные, количество нейронов в каждом слое сети (пока что мы не углубляемся, идем на параметрах “по умолчанию”) и выбранную метрику, которая в процессе обучения будет отслеживаться.
В коде это выглядит следующим образом:
learn = tabular_learner(data, layers=[200,100], metrics=accuracy)
Вот и все, друзья!
Обучение
У нас есть данные. Сплит. Убрано.
Мы выбрали метрику.
Мы выбрали модель.
Теперь пришло время тренироваться! В fast.ai эта операция довольно проста и требует от нас выполнения одного метода объекта Learner: fit_one_cycle().
Из гиперпараметров, которые мы предоставляем на этом этапе, мы имеем
- количество “циклов” обучения
- learning rate – насколько большие шаги должен сделать наш алгоритм в процессе обучения
В общем, задайте количество циклов (я начну с 1), установите скорость обучения 1e-2 и тренируйтесь!
learn.fit_one_cycle(1, 1e-2)Code language: CSS (css)И БАХ! Точность составляет 0,9772!
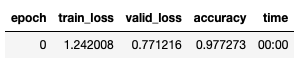
Оценка
В принципе, на предыдущем этапе мы уже получили результат оценки на валидационном множестве. Но что, если мы хотим проверить показатели нашей модели машинного обучения на другом наборе данных?
И снова разработчики fast.ai делают нашу жизнь настолько простой, насколько это возможно. Хотите провести валидацию? Вот так, у вас есть метод validate(). С этим покончено, настало время для CS.
# если мы проверим на множестве, которое мы указали в ученике
learn.validate()
# или, по желанию, мы можем указать набор, например.
learn.validate(learn.data.valid_dl)Code language: CSS (css)Оптимизация гиперпараметров
Если вы не помните, что такое гиперпараметры в процессе обучения модели машинного обучения, то загляните в предыдущий пост – там вы найдете краткое объяснение.
Одним из гиперпараметров, которые мы используем при обучении, является скорость обучения. Как его установить? Вы должны посмотреть на кривые обучения и, основываясь на опыте предыдущих экспериментов, установить их.
Ну, но у нас нет опыта. У нас тоже нет предыдущих экспериментов…
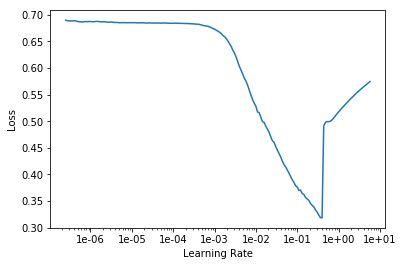
Определение скорости обучения
Было бы неплохо иметь инструмент, который может предложить такую скорость обучения. Мы можем использовать метод поиска скорости обучения – который с помощью коротких экспериментов позволяет нам выбрать скорость обучения для данного случая. В fast.ai мы имеем готовую, “однострочную” реализацию.
Другие гиперпараметры также могут быть “перебраны”. У нас есть такие методы, как поиск по сетке или случайный поиск. Существуют готовые библиотеки, поддерживающие процесс поиска гиперпараметров, например Optuna или Hyperopt. Но мы поговорим об этом подробнее в какой-то момент, потому что это то, за что нужно сесть.
DOD – когда наша модель достаточно хороша
В академических кругах я часто слышал, что ответ на большинство вопросов таков: это зависит от обстоятельств.
Когда наша модель машинного обучения достаточно хороша? Это зависит от…
В начале нашего приключения мы выбрали метрику. В нашем случае это была эффективность (точность). Но какое значение метрики будет удовлетворительным?
Известно, что чем выше, тем лучше. Но вероятность того, что мы достигнем 100%, невелика.
Хотя однажды мне удалось это сделать – тренировка прошла отлично, метрики поднялись до потолка. Я был взволнован, как фонарь на реву. На какое-то время… Конечно, оказалось, что я совершил ошибку и был обманут где-то по пути…..
Возвращаясь назад, в нашем случае мы можем предположить, что когда мы достигнем 90% эффективности, это будет замечательно.
И вот так мы крутим параметры и тренируемся для достижения поставленной цели. А-а-а, машинное обучение….
Получилось ли у нас?
В нашем случае, однако, мы получили очень хорошие результаты с первого выстрела. Вы можете праздновать! У Васи наверняка есть бутылка для такого особого случая.
Предсказания
Как только мы получили модель машинного обучения, которая достигла предполагаемой производительности, пришло время использовать ее в работе. Мы будем использовать нашу модель для выдачи предсказаний миру. Это называется выводом, или запросом к обученной модели для прогнозирования на новых данных.
Здесь небольшое замечание – бывает, что модель для вывода модифицируется по сравнению с той, которая использовалась при обучении. Для оптимизации модели, приведения прогнозов в соответствие с требованиями бизнеса и т.д. используются различные приемы. Об этом мы поговорим как-нибудь потом, а пока…
Использование данных для ответа на вопросы
Вам, вероятно, интересно, как попросить обученную модель машинного обучения сделать прогноз для некоторого набора данных?
В fast.ai это очень просто и требует от вас использования метода get_preds() объекта learner. В такой метод мы передаем набор данных, для которых хотим получить предсказания. И это все!
preds, _ = learn.get_preds(data.valid_ds) pred_prob, pred_class = preds.max(1) pred_prob, pred_class
В дополнение к предсказанным классам мы получаем “вероятность”, с которой модель утверждает, что данный образец принадлежит к данному классу. Это не вероятность в классическом, статистическом смысле, но, вероятно, в польском языке нет лучшего слова для описания этих значений.
Таким образом, мы помогли Васе превратить его хобби в бизнес. Отныне ему не придется дегустировать каждое вино, он просто будет время от времени вручную маркировать несколько бутылок, чтобы через некоторое время проверить модель на основе таких подготовленных данных. Ведь ингредиенты, из которых он делает вино, могут меняться. Приборы могут выйти из строя. Мы можем столкнуться с так называемым дрейфом концепции.
Поэтому помните, что стоит отслеживать показатели модели с течением времени. Для этого нужны данные, описанные человеком, но об этом стоит позаботиться.
